研究の詳細-2025/02/01
研究背景
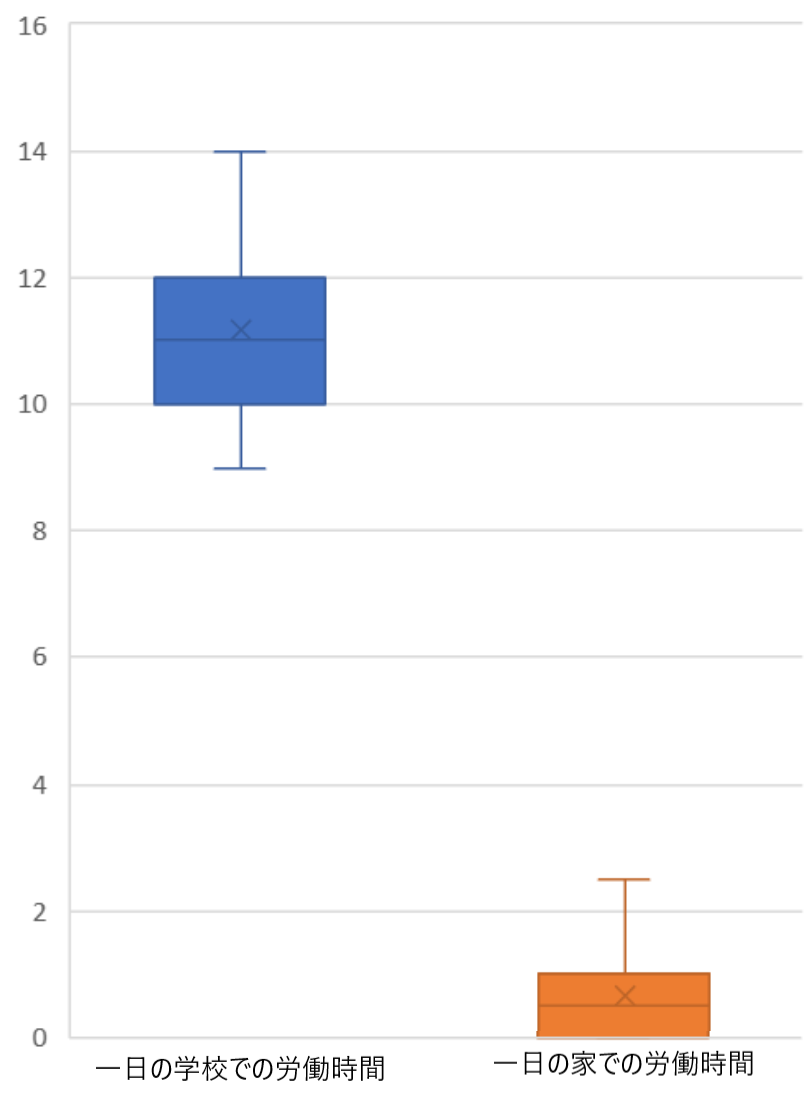
〇教育現場における教員の労働時間の多さ
右は小野高校での教員の平日の労働時間をまとめたものです。平均して11時間程もの労働を一日に行っています。
〇大学入試共通テストで記述式の採用の断念
自己採点での不安、守秘義務などの問題から断念されました。
〇教員によって異なる基準
同じ採点基準でも先生によって捉え方が異なることにより、採点にずれが生じてしまいます。
目的
上記の背景を踏まえて、以下の3つを私たちの目的としました。
〇教員の労働負担の削減
〇公平な視点からの採点
〇家庭学習や大規模な採点へのハードルを下げる
これらの目的を達成するために、私たちは「国語の記述問題において、テキストデータから人間と同じ程度の採点精度を誇るシステムを作ることができる」という仮説のもと実験を進めていきます。
また、これらの目的を達するために今回の研究においては、以下の目的を立てます。
〇家庭学習で使える自動採点システムの作成
〇先生の採点をアシストするシステムの作成
予備実験
まずは予備実験としてどのような方法が最も精度が良いのかを比較します。5点満点の問題を一つ用意し、小野高校の生徒の方々に答えていただきます。その回答に対して以下の5つの方法で採点を行い、それぞれの精度を比較します。
条件は以下の通りです。
条件1,手書きのデータではなく、テキストデータで採点する。
条件2,AIに与えて、採点の参考にするトレーニングデータは50個、精度の測定を行うテストデータは200個とする
条件3,試す方法以下の通りとする
1,国語教員
人間の採点者と比べて他の方法はどれくらい匹敵しているのかを調べるために経験豊富な国語の先生に採点をお願いします。
2,ルールベース型AI
私たちが1から条件を定めて作ったプログラムで、広義的にはAIに含まれます。採点には特定のキーワードが入っていると加点、悪文末、悪文法だと減点という形になっています。この時、キーワドはプログラム制作者の語彙力に依存します。
3,Claude
Anthropic社製の生成AIです。5000〜1万字ほどのスクリプトを採点基準として渡します。今回は、有料版を利用しています。
4,ChatGPT
OpenAI社製の生成AIです。条件は同様としますが、こちらに関しては無料版です。
5,Gemini
Google社製の生成AIです。条件は同様としますが、こちらも無料版となっています。
※この時、生成AIでは基準以外の参考となるすでに採点されたトレーニングデータとして何も与えない「zero-shot学習」と、トレーニングデータとして幾つかの参考とするデータを与える「転移学習」を実験します。
条件4,問題は、日刈あがたさんの「ビッグフットの大きな靴」であり、満点5点、文字数28−35文字、物語における記述であるものとします。
これらの結果は以下の通りです。
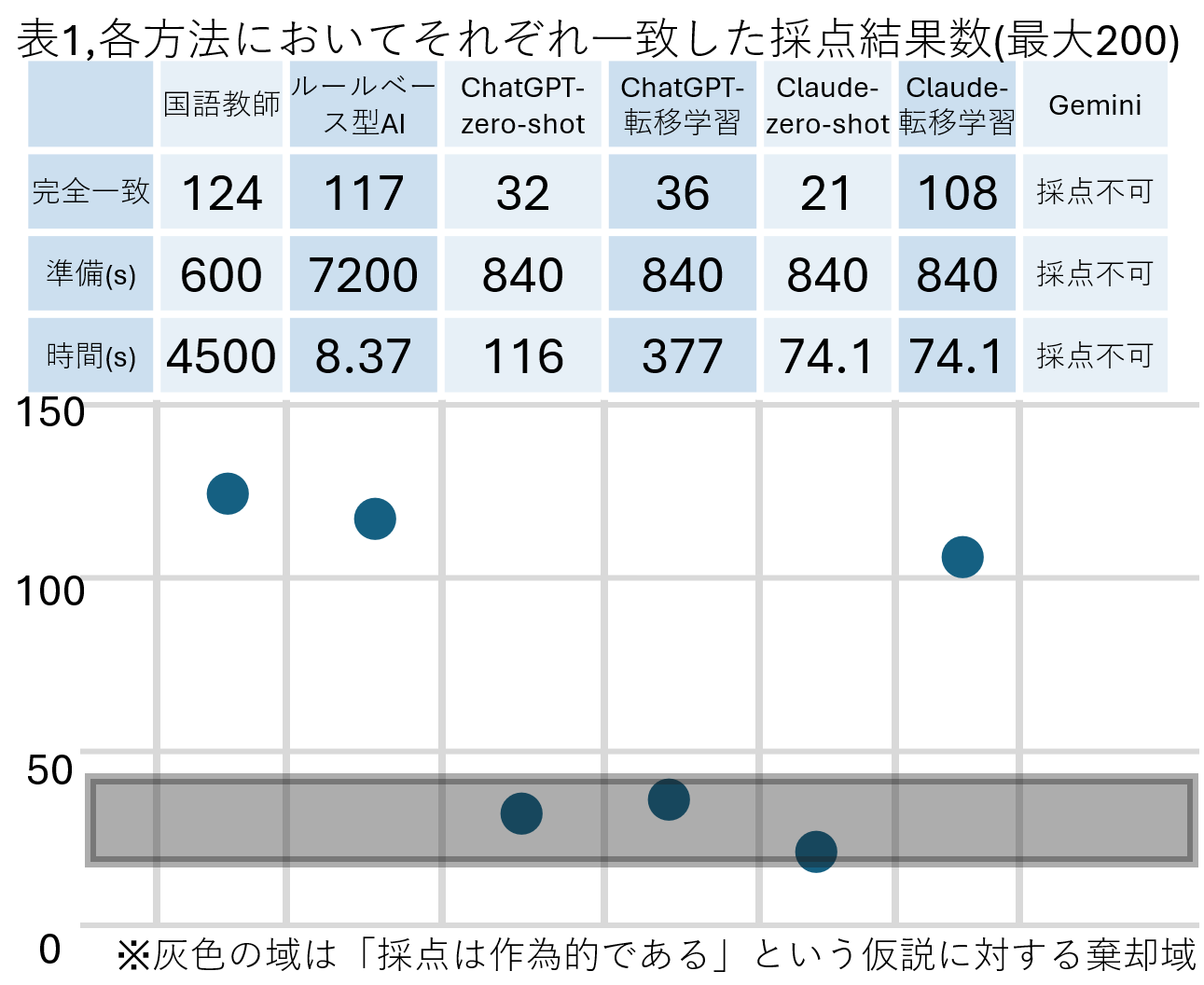
これらの結果から分かることは
①「Claude-zero-shot」、及び「ChatGPT-転移学習」、「ChatGPT-zero-shot」に関しての帰無仮説「採点は作為的である」を立てたときの有意水準99%の棄却域の19.73<=X<=46.93に入っていることから、採点は全くのランダムに行った時と遜色ないということ。
②「Claude-転移学習」、「ルールベース型AI」の二つは先生方の採点に匹敵していることから人間の採点者と同じぐらいの精度で採点ができるということ。
の二つになります。
そして、これらの結果から、「自動採点システムは人間の精度に匹敵しうる」という仮説を立てて今後の実験を行なっていきます。
本実験1
まず、変更した条件は以下の通りです。
1,使用した問題の変更。
①評論形式の「遡する思考」(佐藤卓)、文字数は24-30文字
②評論形式の「森林と人間」(石城謙吉)、文字数は32-40文字
③物語形式の「こころ」(夏目漱石)、文字数は28-35文字
2,用いたトレーニングのデータの数を15個、及びテストデータの数を100個にしたこと。
この時の結果は以下の通りになりました。
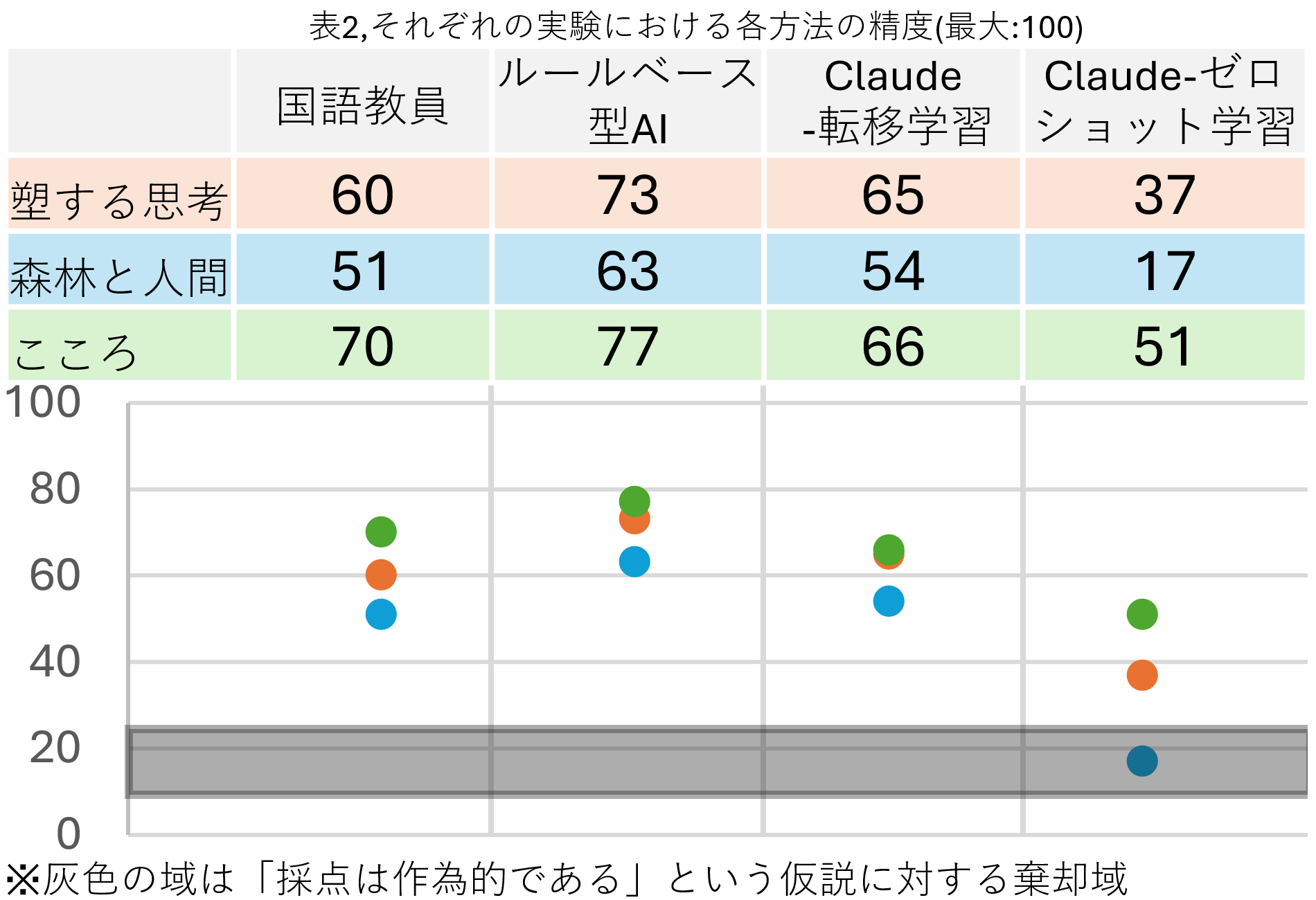
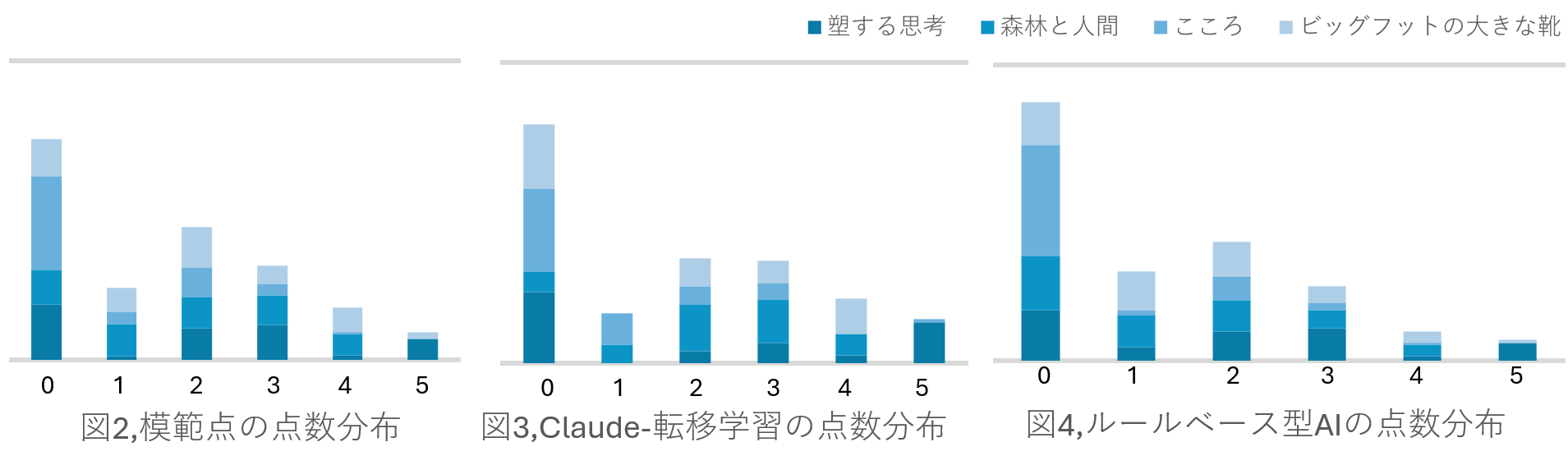
この結果からわかることは
1,「ルールベース型AI」と「Claude-転移学習」は安定して人間に匹敵しうる、つまり、仮説は正しいということ。
2,これら二つの採点方法では振れ幅も小さくなっていることから、安定性も比較的高いということ。
この時、それぞれの問題の平均点や文字数、問題の種類と照らし合わせて見ます。
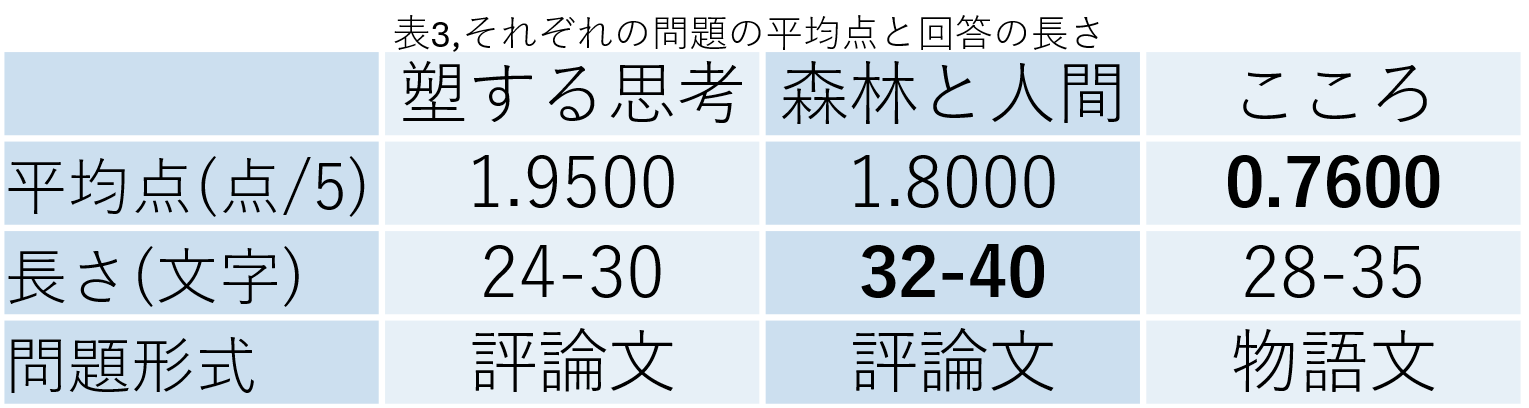
〇最も平均点の低い「こころ」などを見てみると、0点の回答が続出しており、この時採点の精度が総じて高いことから平均点の低さが採点のしやすさにつながっていると考えられます
〇最も文字数の長い「森林と人間」が最も精度が総じて低くなっていることから文章の長さがると精度が下がってしまうということがわかります。
〇予備実験で用いた「ビッグフットの大きな靴」及び「こころ」は物語形式、対して「森林と人間」と「塑する思考」は評論形式になっています。これらの間に大きな差はないことから問題の文章の形式はあまり大きな差は生まないということがわかります。
本実験2
先ほどまでの実験を見る限り全体を通して先生方の採点の精度は超えています。しかしながらその時用いたデータの数は暫定で決めているものに過ぎなかったのでその数の必要数について実験します。結果は以下の通りです。
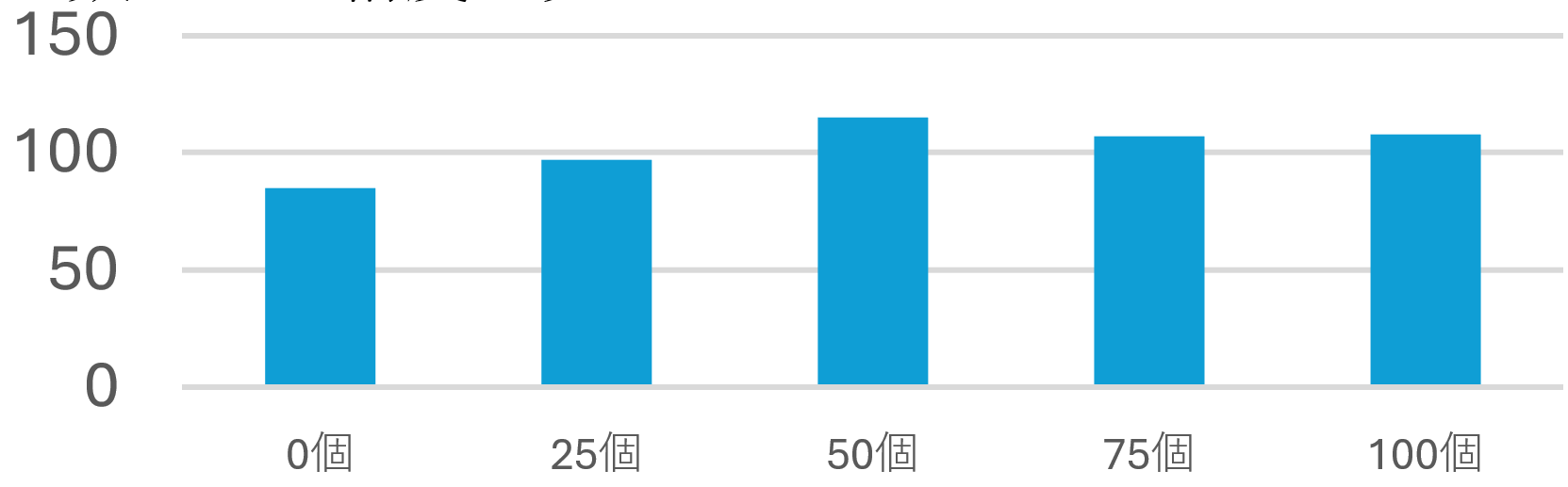
この結果から、0から50個までのデータ数では精度向上がみられるものの、それ以上ではあまり見られないことから、最低50個のトレーニングデータが必須であり、それ以上はあまり精度に影響は出ないということがわかります。
全体のまとめ
〇ルールベース型AIの長所
・自分たちで想定した出力で安定している(同じ文章は同じ点数になる)こと。
・採点基準だけでもある程度物にできること。
〇ルールベース型AIの短所
・イレギュラーに弱い
・採点において一手遅い(後手の)対応を強いられること。
・プログラマーが必須になること。
〇生成AIの長所
・準備をするのはトレーニングデータだけでよいこと。
・日本語を学んでいるのでイレギュラーに強いこと。
・プログラムをする必要がないこと。
〇生成AIの短所
・出力が安定しない(同じ文章に対して異なる点数で採点してしまう)こと。
・より精度を上げようとするとお金が必要(有料版)
・文字数カウントを間違えやすい。
これらのことを踏まえたうえで目的の達成や、より精度の良いシステムを造っていきたいと感じています。
今後の展望
今後は他の方法の模索や、更なる信頼獲得を目標に実験をさらに重ねていきたいと考えています。このページでも自動採点システムの実装例や活用例を公開しています。アンケートも付属しているので実験の一環としてご協力をお願いします。
参考文献
文部科学省公式発表 (2024/10/25閲覧)
使用ライブラリ「Unidic」 (2024/8/15閲覧) Unidic 1.0.8使用
使用ライブラリ「MeCab」 (2024/8/15閲覧) MeCab1.0.9使用
Claude 公式サイト (2024/10/20閲覧) Claude 3.5 Sonnet, Anthropic使用
chatGPT公式サイト (2024/10/20閲覧) chatGPT4, openAI使用
Gemini公式サイト (2024/10/20閲覧) Gemini, Google使用
謝辞
アンケートにご協力いただいた小野高校の先生方、生徒の皆様に御礼を申し上げます。
研究の詳細一覧に戻る